基于深度学习的CMS识别[图像分类]
字数
632 字
阅读时间
3 分钟
更新日期
9/20/2018
这个想法早就有了,之前也有过记录 https://x.hacking8.com/?post=216 自己入门深度学习不久,只会用一些框架和现成的模型。当时的想法是CMS识别本质上是一种图像分类,这类的技术现在已经很成熟,参见各类验证码打码平台,只需要为图像打上标签,用一个成熟的模型,然后训练即可。
基于这个想法,数据集用的基于hash、关键词识别出来的网站,然后写了一个程序批量得到网页的快照用作数据集。最后用caffe框架进行处理,但是由于硬件条件限制,最终失败了。
今天看到ai.baidu.com这个,使用更是简单,只需要给图像打上标签,然后就会自动学习了。
每个分类选取了70~80张图片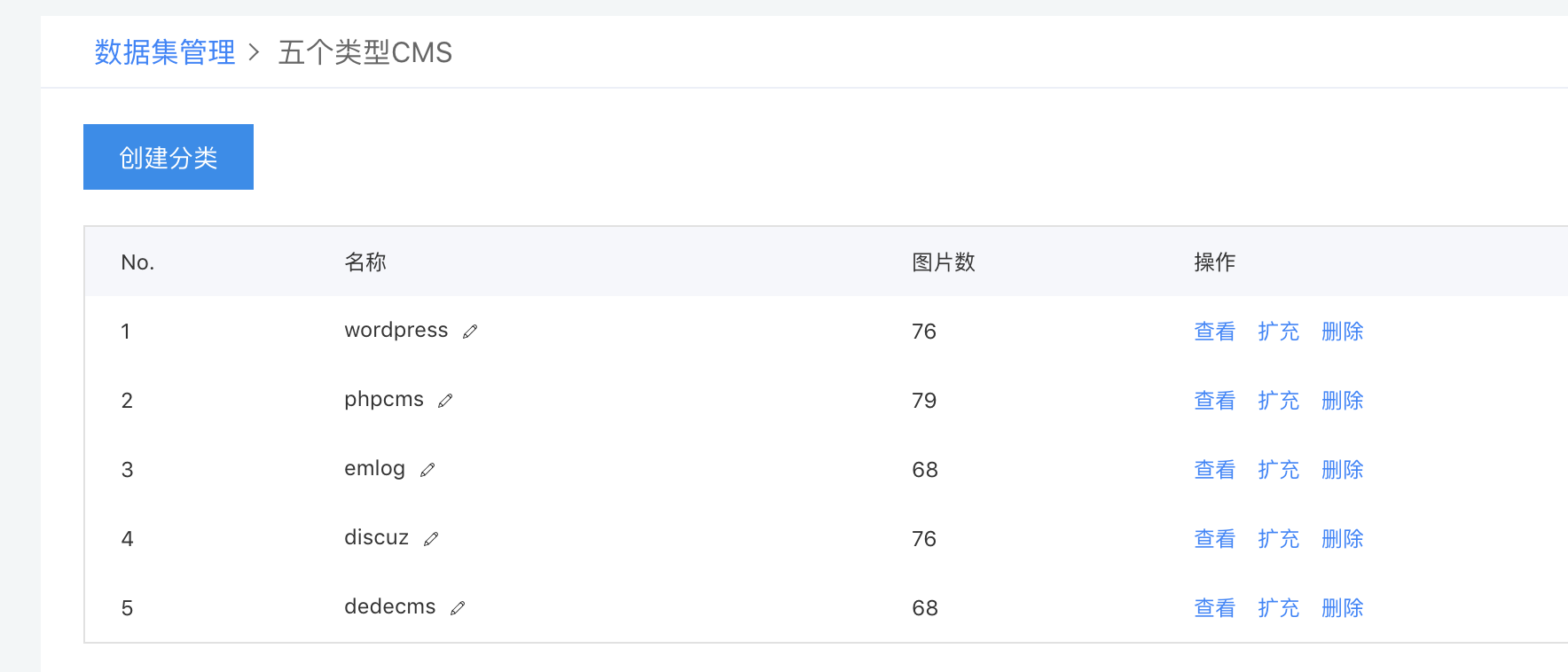
训练集处理
由于快照得出的网页长度宽度不统一,所以为了以后的方便,将长宽统一至800*600
可行性
准确率低,我估计是样本太少了,分类太多了。v1版本两个分类,discuz和dedecms 准确率78%,到v2版本,五个分类,准确率50%左右,深度学习的效果还是有的。在v4版本,我将discuz``dedecms的样本提高到了200+样本,效果得到了明显的提升。从训练结果来看,基本上可以验证这个想法的可行性。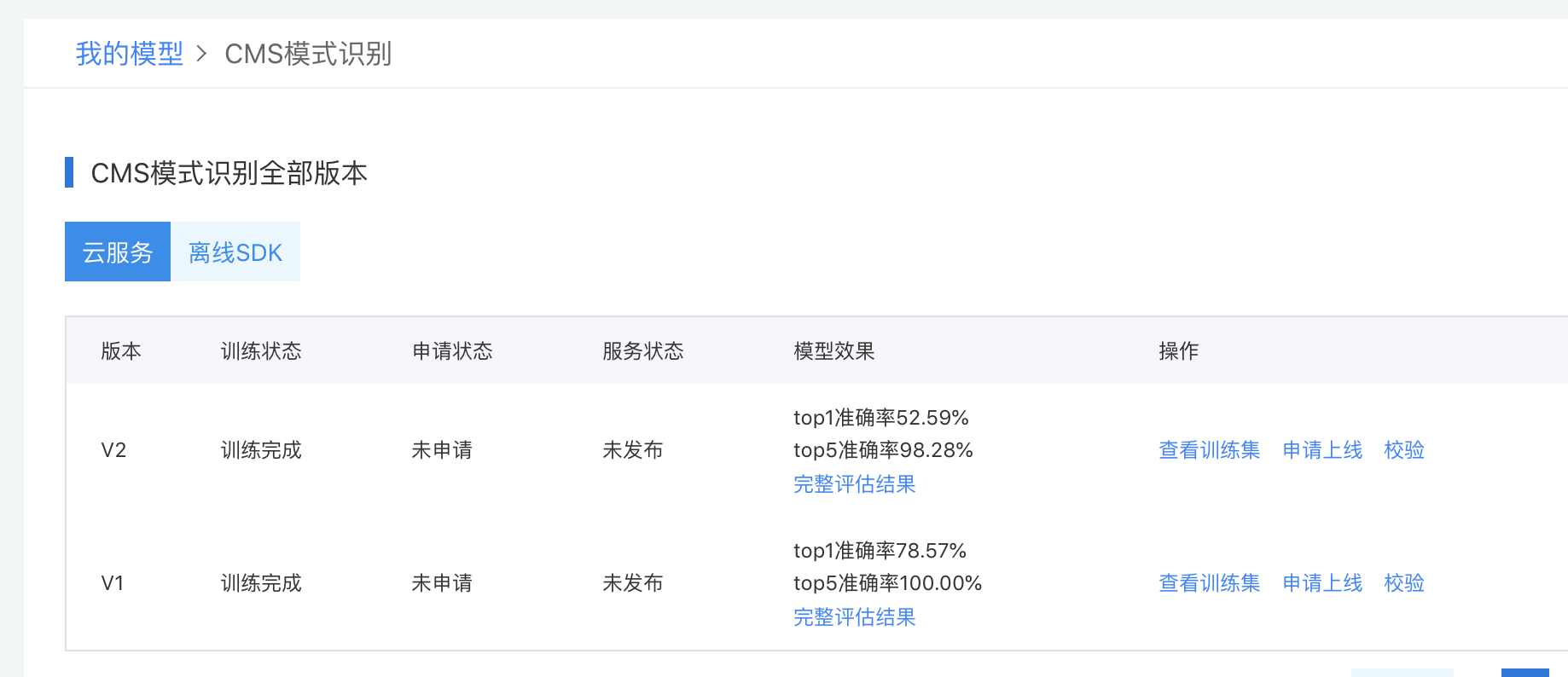
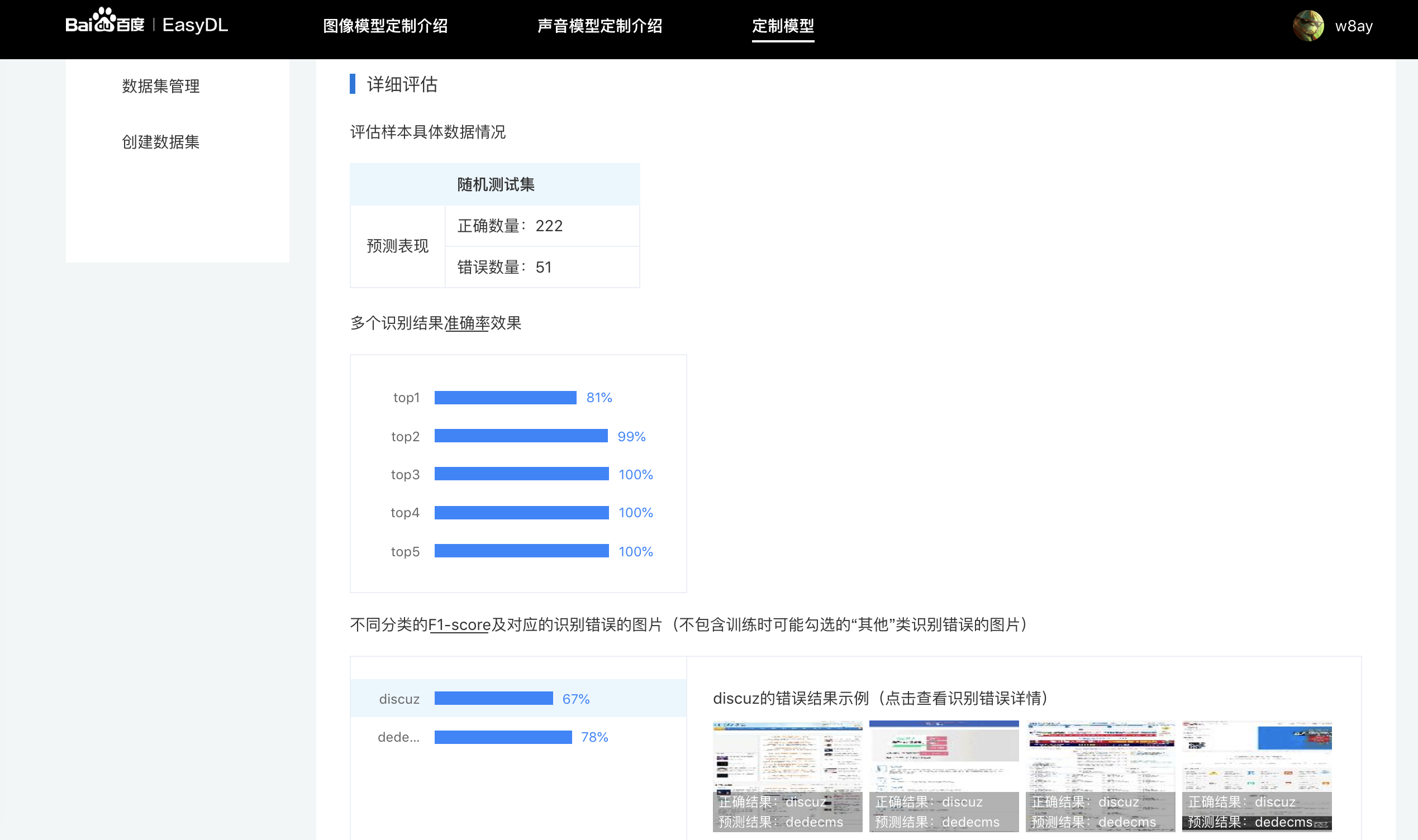
测试
误差还是有许多的。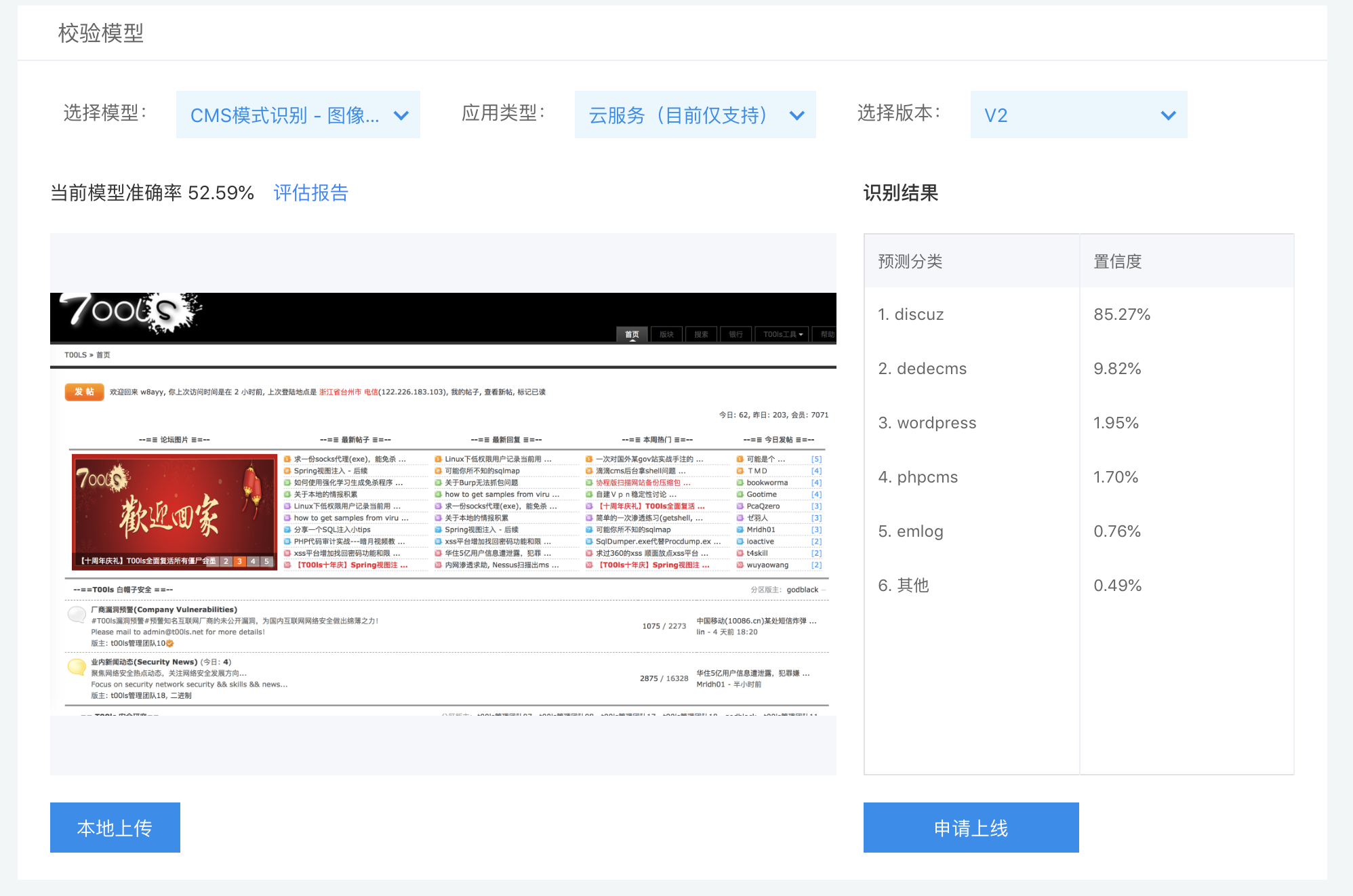
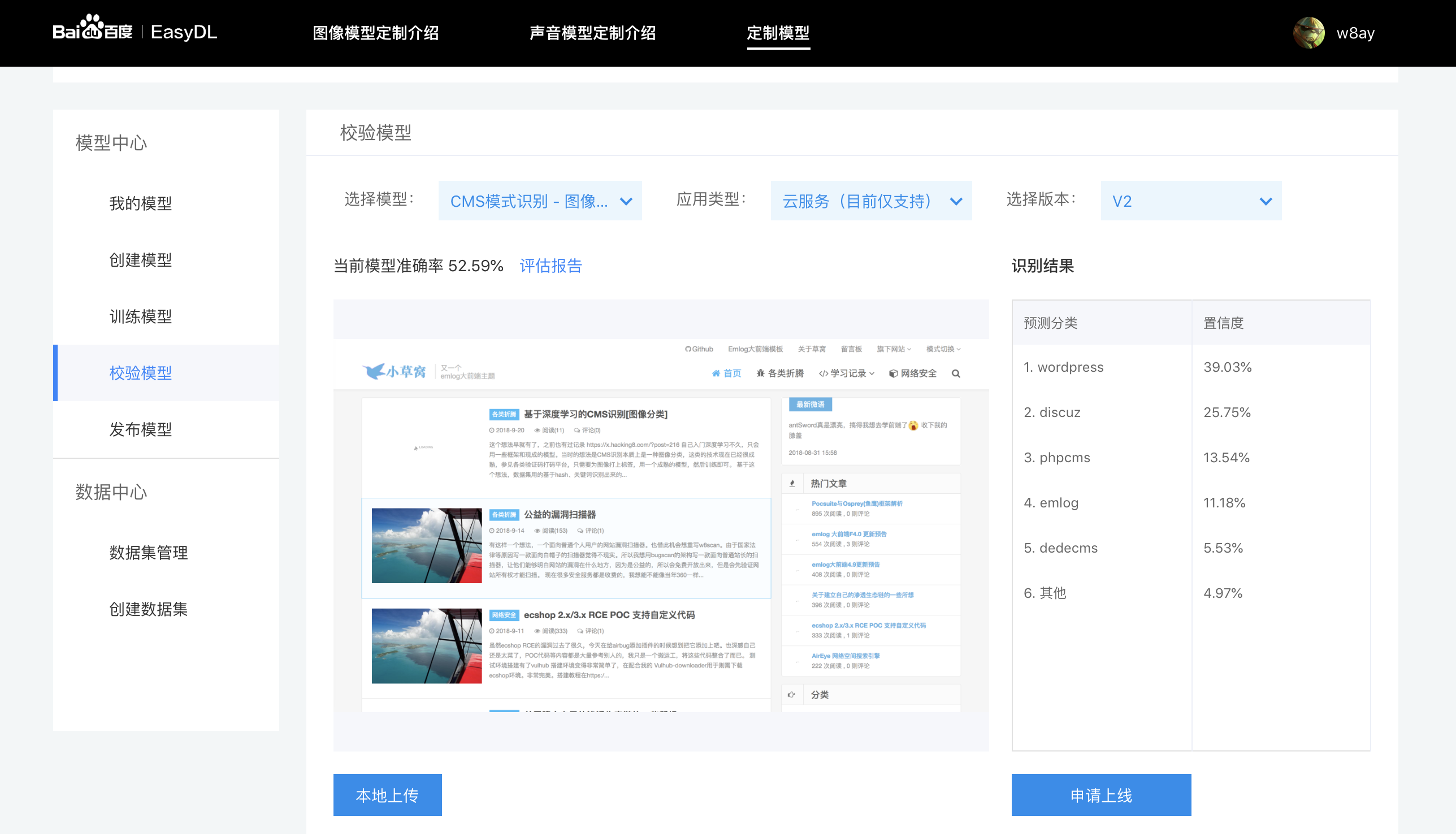
不足
主要是训练集的问题。
- 训练集样本太少
- 训练集在采集的过程中快照是使用的IE内核,有的网站可能已经不支持此内核了,所采集图像有严重的错位,可能影响判断。训练集使用的网站是自己在线平台所收集到的网址,判读根据MD5+关键词,可信度比较高,但是时间有些久远,可能这段时间里有的网站已经更换了程序或者已经无法访问。
这些问题其实是非常好解决的,如果有精力的话我在完善这些数据集。
训练集
开源在了github https://github.com/boy-hack/dl-cms