goby 最新版 指纹提取
字数
532 字
阅读时间
3 分钟
更新日期
8/5/2021
最近想看看最新版的goby指纹提取有没有什么变化。
我们知道了goby的指纹规则是yara写的,并且保存在了crules文件中。
下载了最新版本Beta1.8.279的Goby,显示的更新日期是2021 6.18
查看是用go几版本写的

之前goby内嵌资源用的statik第三方库,尝试搜索这个字符串已经搜不到了。
在go1.16,嵌入资源有个官方实现,叫go embed,可以根据在二进制中搜索embed.FS来确认是否使用了这个特性,所以搜索就知道goby用的这种方式将资源嵌入了程序。
然后自己可以测试一下,使用了go embed,内嵌的资源是怎样的形式存储的,我直接给出我的结论,直接明文显示在二进制中。
搜索YARA就能找到yara的头
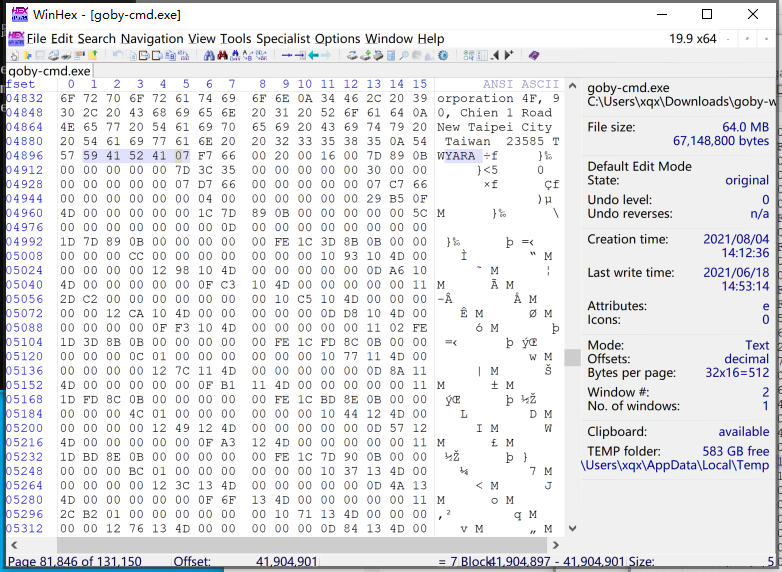
往下翻就能看到熟悉的规则~
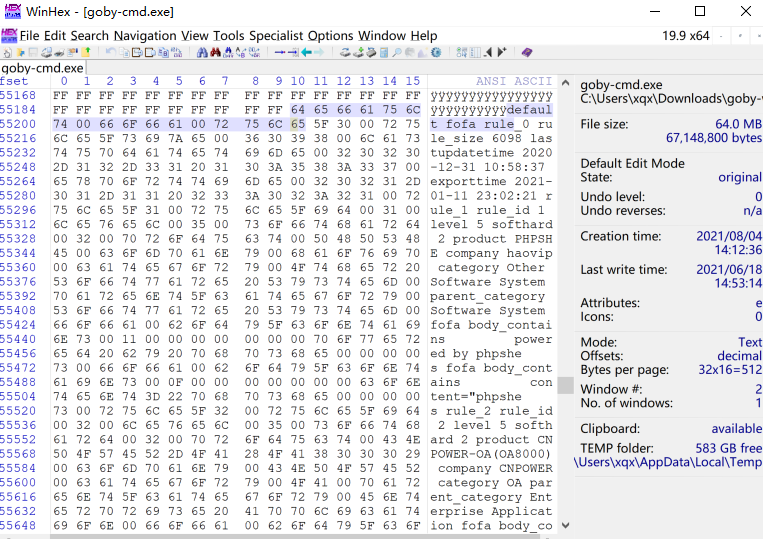
另外看到goby使用了这个库https://github.com/hillu/go-yara,应该就是用来解析规则的,看这个库的实现,它只是c版本源码的封装。
如果只是想使用把yara提取出来用这个库应该就能用了,但我的目的还是把指纹提取出来。
后面规则的提取就和我之前文章中的一样了,完整提取代码
python
filename = r"goby-cmd.exe"
with open(filename, 'rb') as f:
data = f.read()
start = data.index(b"default\x00fofa")
end = data.index(b"\x00" * 16, start)
data = data[start:end]
datas = data.split(b"rule_id")[1:]
sep = b"\x00"
options_set = set()
results = []
for item in datas:
ff = item.split(sep)
# print(ff)
rule_id = ff[1].decode()
level = ff[3].decode()
softhard = ff[5].decode()
product = ff[7].decode()
company = ff[9].decode()
category = ff[11].decode()
parent_category = ff[13].decode()
# print(rule_id, level, softhard, product, company, category, parent_category)
dd = {
"rule_id": rule_id,
"level": level,
"softhard": softhard,
"product": product,
"company": company,
"category": category,
"parent_category": parent_category,
"rules": []
}
bb = b'\x00'.join(ff[14:])
s = bb.split(b'\x00\x00\x00\x00\x73\x00')
_rr2 = []
for rr in s:
_rules = []
if not rr.startswith(b'fofa'):
continue
index = 0
while index < len(rr):
prefixx = b"fofa\x00"
try:
start = rr.index(prefixx, index) + len(prefixx)
except:
break
end = rr.index(b'\x00', start)
match_way = rr[start:end].decode()
# print("match_way", match_way)
_length = rr[end + 1]
content = rr[end + 9:end + 9 + _length]
index += end + 9 + _length
# _rules.append(match_way + ":" + content.decode('utf-8', errors="ignore"))
_rules.append(
{
"match": match_way,
"content": content.decode('utf-8', errors="ignore")
}
)
_rr2.append(_rules)
dd["rules"] = _rr2
results.append(dd)
print(results)
with open("fofa.json", "w", encoding="utf-8") as f:
import json
json.dump(results, f, ensure_ascii=False)