用Python构建PE文件
用Python生成一个PE文件,主要是为了学习PE格式,因为看很多红队工具的原理都要掌握这个,这篇文章主要是记录调试代码的过程。
主要使用的是Python3。
有关PE的文件结构描述,之前写过一个简短的对每个字段的描述
- 模仿cs开局一个shellcode的实现.md - 小草窝博客 (hacking8.com)
- 描述pe格式的主要地方是
winnt.h,其中有一节叫做Image Format,该节给出了DOS MZ格式和Windows 3.1 NE格式的文件头,之后就是PE文件的内容。在这个文件中几乎能找到所有关于PE文件的数据结构定义、枚举类型、常量定义。 - EXE文件和Dll文件是语义上的,它们使用完全的相同的PE格式,唯一的区别就是用一个字段标识这个是EXE还是DLL。
第一版 PE+ShellCode
照着PE结构的描述,用Python实现了,PE格式每个字段都有对应的大小,用到了struct库。
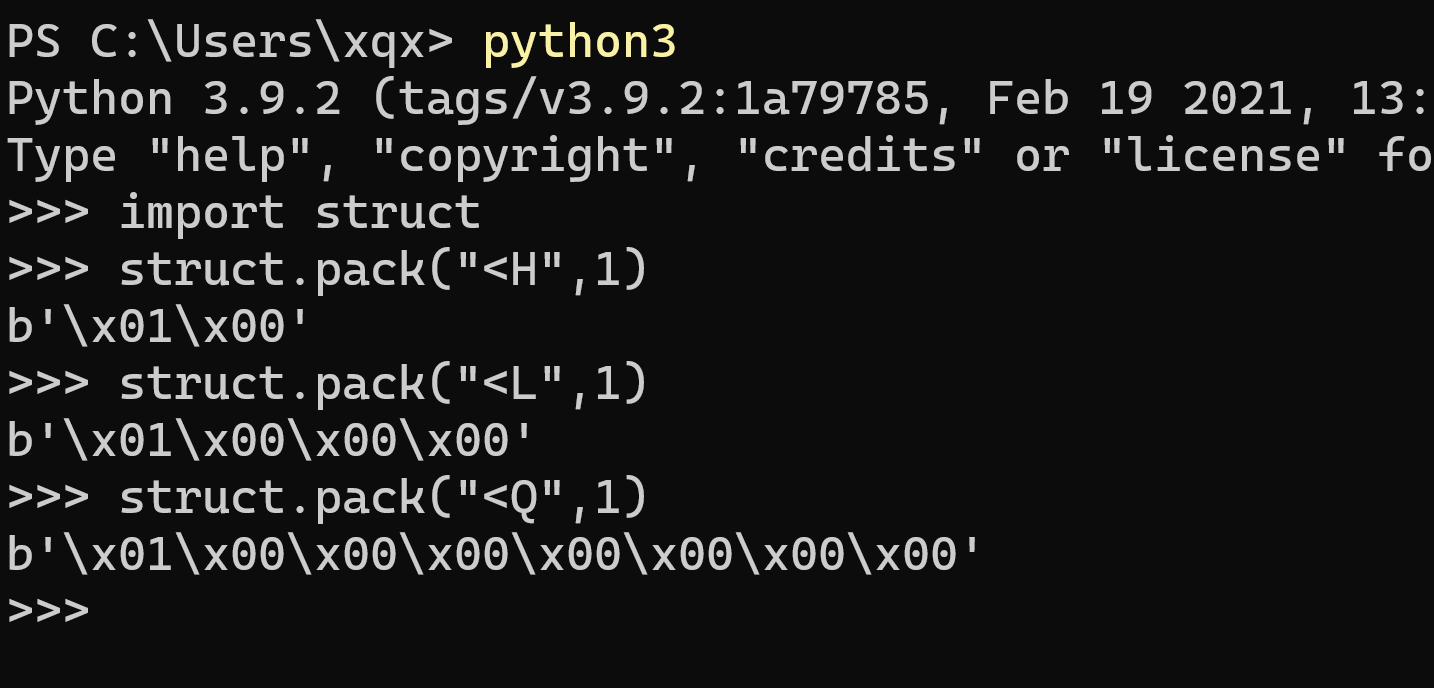
一个简要的例子,因为Windows一般字符存储都是小端模式,所以用<标明,后面的字母代表将数值转换的大小
Hunsigned short 占2byteLunsigned long 占 4byteQunsigned long long 占8byte
然后用msf生成一个shellcode,到时候直接填入代码段
$ msfvenom -a x86 -p windows/exec CMD="calc" -f python
[-] No platform was selected, choosing Msf::Module::Platform::Windows from the payload
No encoder specified, outputting raw payload
Payload size: 189 bytes
Final size of python file: 932 bytes
buf = b""
buf += b"\xfc\xe8\x82\x00\x00\x00\x60\x89\xe5\x31\xc0\x64\x8b"
buf += b"\x50\x30\x8b\x52\x0c\x8b\x52\x14\x8b\x72\x28\x0f\xb7"
buf += b"\x4a\x26\x31\xff\xac\x3c\x61\x7c\x02\x2c\x20\xc1\xcf"
buf += b"\x0d\x01\xc7\xe2\xf2\x52\x57\x8b\x52\x10\x8b\x4a\x3c"
buf += b"\x8b\x4c\x11\x78\xe3\x48\x01\xd1\x51\x8b\x59\x20\x01"
buf += b"\xd3\x8b\x49\x18\xe3\x3a\x49\x8b\x34\x8b\x01\xd6\x31"
buf += b"\xff\xac\xc1\xcf\x0d\x01\xc7\x38\xe0\x75\xf6\x03\x7d"
buf += b"\xf8\x3b\x7d\x24\x75\xe4\x58\x8b\x58\x24\x01\xd3\x66"
buf += b"\x8b\x0c\x4b\x8b\x58\x1c\x01\xd3\x8b\x04\x8b\x01\xd0"
buf += b"\x89\x44\x24\x24\x5b\x5b\x61\x59\x5a\x51\xff\xe0\x5f"
buf += b"\x5f\x5a\x8b\x12\xeb\x8d\x5d\x6a\x01\x8d\x85\xb2\x00"
buf += b"\x00\x00\x50\x68\x31\x8b\x6f\x87\xff\xd5\xbb\xf0\xb5"
buf += b"\xa2\x56\x68\xa6\x95\xbd\x9d\xff\xd5\x3c\x06\x7c\x0a"
buf += b"\x80\xfb\xe0\x75\x05\xbb\x47\x13\x72\x6f\x6a\x00\x53"
buf += b"\xff\xd5\x63\x61\x6c\x63\x00"完整代码
# 学习pe的最好方法,就是自己写一个PE文件。这个例子展示了用python生成一个pe文件
import struct
import time
MZ_MAGIC = 0x5A4D
PE_MAGIC = 0x4550
IMAGE_FILE_MACHINE_I386 = 0x014c
IMAGE_SCN_MEM_EXECUTE = 0x20000000 # Section is executable.
IMAGE_SCN_MEM_READ = 0x40000000 # Section is readable.
IMAGE_SCN_MEM_WRITE = 0x80000000 # Section is writeable.
IMAGE_SCN_CNT_CODE = 0x00000020
IMAGE_SCN_CNT_INITIALIZED_DATA = 0x00000040
class DOS_HEADER_32(object):
'''
DOS头只关心 magic 和 e_lfanew 位置就行
'''
e_magic = MZ_MAGIC
e_cblp, e_cp, e_crlc, e_cparhdr, e_minalloc, e_maxalloc, e_ss, e_sp, \
e_csum, e_ip, e_cs, e_lfarlc, e_ovno, e_res, e_oemid, \
e_oeminfo, e_res2, e_lfanew = [0] * 18
def __init__(self):
self.fmt = "<30HL"
# 小端模式 30个H(unsigned short 占2byte) 后一个是L(unsigned long 占 4byte)
self.e_res = [0, 0, 0, 0]
self.e_res2 = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
def raw(self):
return struct.pack(self.fmt, self.e_magic, self.e_cblp, self.e_cp,
self.e_crlc, self.e_cparhdr, self.e_minalloc,
self.e_maxalloc, self.e_ss, self.e_sp, self.e_csum,
self.e_ip, self.e_cs, self.e_lfarlc, self.e_ovno,
self.e_res[0], self.e_res[1], self.e_res[2], self.e_res[3],
self.e_oemid, self.e_oeminfo,
self.e_res2[0], self.e_res2[1], self.e_res2[2], self.e_res2[3],
self.e_res2[4], self.e_res2[5], self.e_res2[6], self.e_res2[7],
self.e_res2[8], self.e_res2[9], self.e_lfanew)
# e_lfanew是文件偏移
def getPEOffset(self):
return self.e_lfanew
def getSize(self):
'''
DOS头,SIZE:30*2+1*4=64
:return:
'''
return struct.calcsize(self.fmt)
class IMAGE_NT_HEADER_32(object):
def __init__(self):
self.Signature = PE_MAGIC
self.file_header = self.IMAGE_FILE_HEADER()
self.optional_header = self.IMAGE_OPTIONAL_HEADER32()
def getSize(self):
'''
PE文件头,SIZE:4+20+224=248
:return:
'''
return 4 + self.file_header.getSize() + self.optional_header.getSize()
def raw(self):
return struct.pack("<L", self.Signature) + self.file_header.raw() + self.optional_header.raw()
class IMAGE_FILE_HEADER:
Machine, \
NumberOfSections, \
TimeDateStamp, \
PointerToSymbolTable, \
NumberOfSymbols, \
SizeOfOptionalHeader, \
Characteristics = IMAGE_FILE_MACHINE_I386, 0, 0, 0, 0, 0, 0
def __init__(self):
self.fmt = "<2H3L2H"
def getSize(self):
'''
PE文件逻辑分布的信息,SIZE:2*2+3*4+2*2=20
:return:
'''
return struct.calcsize(self.fmt)
def raw(self):
return struct.pack(self.fmt, self.Machine,
self.NumberOfSections,
self.TimeDateStamp,
self.PointerToSymbolTable,
self.NumberOfSymbols,
self.SizeOfOptionalHeader,
self.Characteristics)
class IMAGE_OPTIONAL_HEADER32:
Magic = 0x10b # 32位为0x10B,64位为0x20B,ROM镜像为0x107
MajorLinkerVersion = 0
MinorLinkerVersion = 0
SizeOfCode = 0 # 一般放在“.text”节里。如果有多个代码节的话,它是所有代码节的和。必须是FileAlignment的整数倍,是在文件里的大小。
SizeOfInitializedData = 0
SizeOfUninitializedData = 0
AddressOfEntryPoint = 0 # 代码入口点的偏移量,RVA
BaseOfCode = 0 # 代码基址,可执行代码的偏移值,RVA
BaseOfData = 0 # 数据基址,已初始化数据的偏移值,RVA
ImageBase = 0 # 程序默认装入基地址,提供整个二进制文件包括所有头的优先(线性)载入地址,RVA
SectionAlignment = 0
FileAlignment = 0
MajorOperatingSystemVersion = 0
MinorOperatingSystemVersion = 0
MajorImageVersion = 0
MinorImageVersion = 0
MajorSubsystemVersion = 4
MinorSubsystemVersion = 0
Win32VersionValue = 0
SizeOfImage = 0 # 内存中整个PE映像体的尺寸。它是所有头和节经过节对齐处理后的大小。
SizeOfHeaders = 0 # DOS头、PE头、区块表的总大小,也就等于文件尺寸减去文件中所有节的尺寸。可以以此值作为PE文件第一节的文件偏移量。
CheckSum = 0 # 映像效验和
Subsystem = 2 # 文件子系统,NT用来识别PE文件属于哪个子系统。 对于大多数Win32程序,只有两类值: Windows GUI 和Windows CUI (控制台)。
DllCharacteristics = 0
SizeOfStackReserve = 0
SizeOfStackCommit = 0
SizeOfHeapReserve = 0
SizeOfHeapCommit = 0
LoaderFlags = 0
NumberOfRvaAndSizes = 0x10 # 指定DataDirectory的数组个数,由于以前发行的Windows NT的原因,它只能为16。 -> 00 00 00 10
DATA_DIRECTORY = []
def __init__(self):
self.fmt = "<HBB9L6H4L2H6L"
def getSize(self):
'''
SIZE:19*4+9*2+2*1+16*8=224
:return:
'''
selfsize = struct.calcsize(self.fmt)
for image_data in self.DATA_DIRECTORY:
selfsize += image_data.getSize()
return selfsize
def raw(self):
selfdata = struct.pack(self.fmt, self.Magic,
self.MajorLinkerVersion,
self.MinorLinkerVersion,
self.SizeOfCode,
self.SizeOfInitializedData,
self.SizeOfUninitializedData,
self.AddressOfEntryPoint,
self.BaseOfCode,
self.BaseOfData,
self.ImageBase,
self.SectionAlignment,
self.FileAlignment,
self.MajorOperatingSystemVersion,
self.MinorOperatingSystemVersion,
self.MajorImageVersion,
self.MinorImageVersion,
self.MajorSubsystemVersion,
self.MinorSubsystemVersion,
self.Win32VersionValue,
self.SizeOfImage,
self.SizeOfHeaders,
self.CheckSum,
self.Subsystem,
self.DllCharacteristics,
self.SizeOfStackReserve,
self.SizeOfStackCommit,
self.SizeOfHeapReserve,
self.SizeOfHeapCommit,
self.LoaderFlags,
self.NumberOfRvaAndSizes)
for image_data in self.DATA_DIRECTORY:
selfdata += image_data.raw()
return selfdata
class IMAGE_DATA_DIRECTORY:
VirtualAddress = 0
Size = 0
def __init__(self):
pass
def raw(self):
return struct.pack("<2L", self.VirtualAddress, self.Size)
def getSize(self):
return 0x4 * 2
class Section:
def __init__(self):
self.fmt = "<LLLLLLHHL"
self.Name = ""
self.VirtualSize = self.VirtualAddress = self.SizeOfRawData = self.PointerToRawData = \
self.PointerToRelocations = self.PointerToLinenumbers = \
self.NumberOfRelocations = self.NumberOfLinenumbers = \
self.Characteristics = 0
# VirtualSize 被实际使用的区块大小,也可是PhysicalAddress,在可执行文件中,它是内容的大小.在目标文件中,它是内容重定位到的地址;
# VirtualAddress 区块的RAV地址(相对虚拟地址)。,节中数据的RVA。
# SizeOfRawData 该块在磁盘中所占的大小,原始数据大小,经过文件对齐处理后节尺寸,PE装载器提取本域值了解需映射入内存的节字节数
# PointerToRawData 该块在磁盘文件中的偏移,文件偏移,这是节基于文件的偏移量,PE装载器通过本域值找到节数据在文件中的位置。
def getSize(self):
return struct.calcsize(self.fmt) + 8
def has(self, rva, imagebase=0):
return (self.VirtualAddress + imagebase) <= rva < (self.VirtualAddress + self.VirtualSize + imagebase)
def hasOffset(self, offset):
return self.PointerToRawData <= offset < (self.PointerToRawData + self.VirtualSize)
def raw(self):
self.Name = (self.Name + "\x00" * (8 - len(self.Name)))[:8]
return self.Name.encode() + struct.pack(self.fmt, self.VirtualSize,
self.VirtualAddress, self.SizeOfRawData, self.PointerToRawData,
self.PointerToRelocations, self.PointerToLinenumbers,
self.NumberOfRelocations, self.NumberOfLinenumbers,
self.Characteristics)
class ImportDescriptor:
def __init__(self):
self.fmt = "<LLLLL"
self.OriginalFirstThunk = self.TimeDateStamp = self.ForwarderChain = self.Name = \
self.FirstThunk = 0
def raw(self):
return struct.pack(self.fmt, self.OriginalFirstThunk, self.TimeDateStamp, self.ForwarderChain, self.Name, \
self.FirstThunk)
def getSize(self):
return struct.calcsize(self.fmt)
# typedef struct _IMAGE_THUNK_DATA32 {
# union {
# DWORD ForwarderString; // PBYTE
# DWORD Function; // PDWORD
# DWORD Ordinal;
# DWORD AddressOfData; // PIMAGE_IMPORT_BY_NAME
# } u1;
# } IMAGE_THUNK_DATA32;
class ImageThunkData32:
Function = 0
def getSize(self):
return 4
def raw(self):
return struct.pack("<L", self.Function)
class ImageImportByName:
def __init__(self):
self.fmt = "<H"
self.Hint = 0
self.Name = ""
def getSize(self):
size = len(self.Name) + 3 # 1 for \0 + 2 for Hint
if size % 2:
size += 1 # Padding
return size
def raw(self):
raw = struct.pack(self.fmt, self.Hint) + self.Name.encode() + b"\x00"
if len(raw) % 2:
raw += "\0" # padding
return raw
def align(idx, aligment):
return (idx + aligment) & ~(aligment - 1)
def dword(v):
return struct.pack("<L", v)
if __name__ == '__main__':
length = 0
mz = DOS_HEADER_32()
mz.e_lfanew = mz.getSize()
length += mz.getSize()
# 设置pe头入口
pe = IMAGE_NT_HEADER_32()
pe.file_header.NumberOfSections = 1 # section数量
pe.file_header.TimeDateStamp = int(time.time())
pe.file_header.Characteristics = 1 + 2 + 4 + 256
# refer https://blog.csdn.net/qiming_zhang/article/details/7309909#3.2.2
pe.optional_header.AddressOfEntryPoint = 0x1000
pe.optional_header.ImageBase = 0x400000
pe.optional_header.SectionAlignment = 0x1000
pe.optional_header.FileAlignment = 0x200
for i in range(pe.optional_header.NumberOfRvaAndSizes):
pe.optional_header.DATA_DIRECTORY.append(pe.IMAGE_DATA_DIRECTORY())
pe.file_header.SizeOfOptionalHeader = pe.optional_header.getSize()
length += pe.getSize()
# .text section
text = Section()
text.Name = ".text"
text.Characteristics = IMAGE_SCN_CNT_CODE | IMAGE_SCN_MEM_READ | IMAGE_SCN_MEM_EXECUTE
text.VirtualAddress = 0x1000
# .rdataracteristics = IMAGE_SCN_CNT_INITIALIZED_DATA | IMAGE_SCN_MEM_READ
length += text.getSize()
# pading
pe.optional_header.SizeOfHeaders = align(length, pe.optional_header.FileAlignment)
padding = (pe.optional_header.SizeOfHeaders - length) * b'\x00'
length = pe.optional_header.SizeOfHeaders
# 写入text代码
buf = b""
buf += b"\xfc\xe8\x82\x00\x00\x00\x60\x89\xe5\x31\xc0\x64\x8b"
buf += b"\x50\x30\x8b\x52\x0c\x8b\x52\x14\x8b\x72\x28\x0f\xb7"
buf += b"\x4a\x26\x31\xff\xac\x3c\x61\x7c\x02\x2c\x20\xc1\xcf"
buf += b"\x0d\x01\xc7\xe2\xf2\x52\x57\x8b\x52\x10\x8b\x4a\x3c"
buf += b"\x8b\x4c\x11\x78\xe3\x48\x01\xd1\x51\x8b\x59\x20\x01"
buf += b"\xd3\x8b\x49\x18\xe3\x3a\x49\x8b\x34\x8b\x01\xd6\x31"
buf += b"\xff\xac\xc1\xcf\x0d\x01\xc7\x38\xe0\x75\xf6\x03\x7d"
buf += b"\xf8\x3b\x7d\x24\x75\xe4\x58\x8b\x58\x24\x01\xd3\x66"
buf += b"\x8b\x0c\x4b\x8b\x58\x1c\x01\xd3\x8b\x04\x8b\x01\xd0"
buf += b"\x89\x44\x24\x24\x5b\x5b\x61\x59\x5a\x51\xff\xe0\x5f"
buf += b"\x5f\x5a\x8b\x12\xeb\x8d\x5d\x6a\x01\x8d\x85\xb2\x00"
buf += b"\x00\x00\x50\x68\x31\x8b\x6f\x87\xff\xd5\xbb\xf0\xb5"
buf += b"\xa2\x56\x68\xa6\x95\xbd\x9d\xff\xd5\x3c\x06\x7c\x0a"
buf += b"\x80\xfb\xe0\x75\x05\xbb\x47\x13\x72\x6f\x6a\x00\x53"
buf += b"\xff\xd5\x63\x61\x6c\x63\x00"
section_text = buf
text.VirtualSize = len(section_text)
text.SizeOfRawData = align(text.VirtualSize, pe.optional_header.SectionAlignment)
text.PointerToRawData = length
section_text += b"\x00" * (text.SizeOfRawData - len(section_text))
length += len(section_text)
# 最后数据的完善
pe.optional_header.SizeOfImage = align(length,
pe.optional_header.SectionAlignment) # // Image大小,内存中整个PE文件的映射的尺寸,可比实际的值大,必须是SectionAlignment的整数倍
# 生成二进制
code = b""
code += mz.raw()
code += pe.raw()
# 生成section代码
code += text.raw()
code += padding
# 生成每个section具体代码
code += section_text
print(code)
with open("test.exe", "wb") as f:
f.write(code)这个是第一版本的代码,详细描述了PE文件的组装流程
- 先初始化
DOS_HEADER_32() - 再
IMAGE_NT_HEADER_32() - 再定义
section字段 - 再根据
文件对齐字段补充0对齐 - 再填写section字段的具体代码
我是直接对text字段填入了shellcode(32位),这样一个PE文件就组装好了。
但是生成出来的文件有几kb太大了。原因是文件的section需要字节对齐
text.SizeOfRawData = align(text.VirtualSize, pe.optional_header.SectionAlignment)SizeOfRawData 要和SectionAlignment对齐才行,就导致了体积膨胀,修改SectionAlignment的大小竟然就无法运行了。但是看到有其他的程序SectionAlignment是可以设置得很小的
后面无意间用lordPE进行修复PE,发现它自动PE大小缩小并且能够运行了。于是我对比了两个文件找到了原因。
text.SizeOfRawData是根据文件对齐的字段来对齐的,我用节对齐的字段对齐了。第一个
sizeofimage字段我设置的太小了(代码问题,我是根据文件的长度对齐section的)导入表段不用对齐文件长度,这个很神奇,text段对齐就好了,导入表字段看lordPE是直接将后面填充
\x00的去掉了 (这个后面有加导入表的PE格式)
修改SectionAlignment的大小竟然就无法运行了
这个的主要原因是sizeofimage设置得太小了
最后sizeOfImage修改为
pe.optional_header.SizeOfImage = pe.optional_header.SizeOfHeaders + align(text.SizeOfRawData,pe.optional_header.SectionAlignment) + align(rdata.SizeOfRawData, pe.optional_header.SectionAlignment)第二版 x86 PE + 导入表
上一个版本使用了shellcode执行命令,这个版本直接通过导入表来调用API
有一个坑,MessageBoxA需要ansi编码的字符串,MessageBoxW需要utf-16编码的字符串,而python3是utf-8编码,所以对字符串变量处理的时候要转换一下
""..encode("mbcs")ansi编码.encode("UTF-16")utf16编码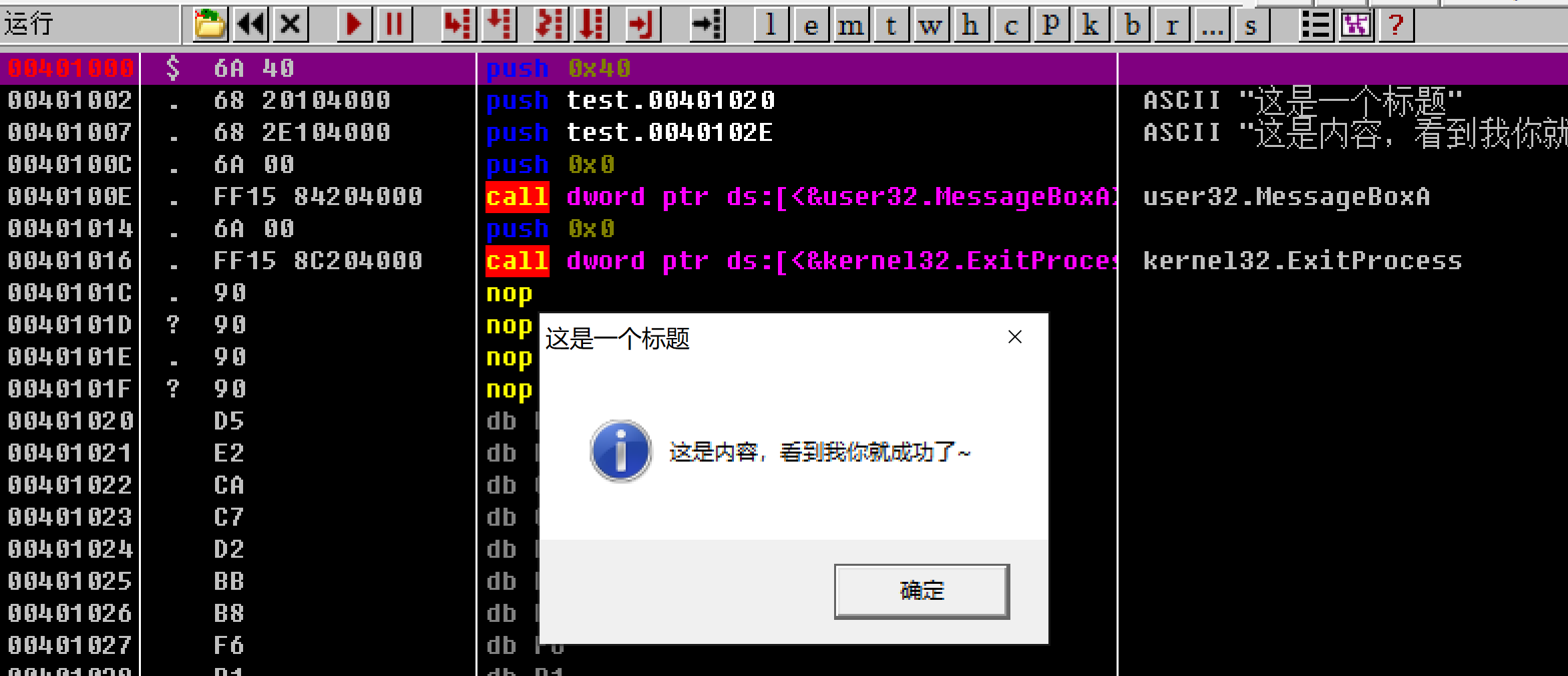
x86 生成的文件1kb左右 (文件对齐默认是512,我尝试将它改小一些,但是会报错)
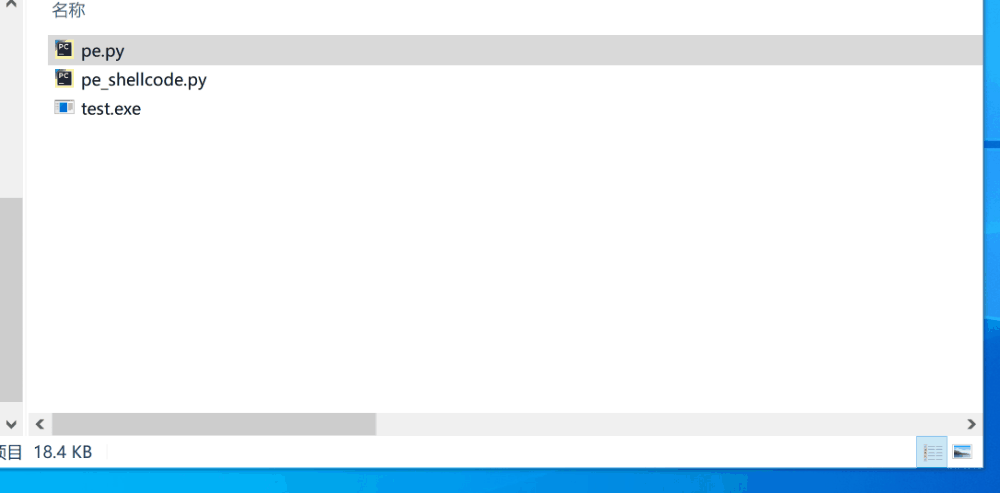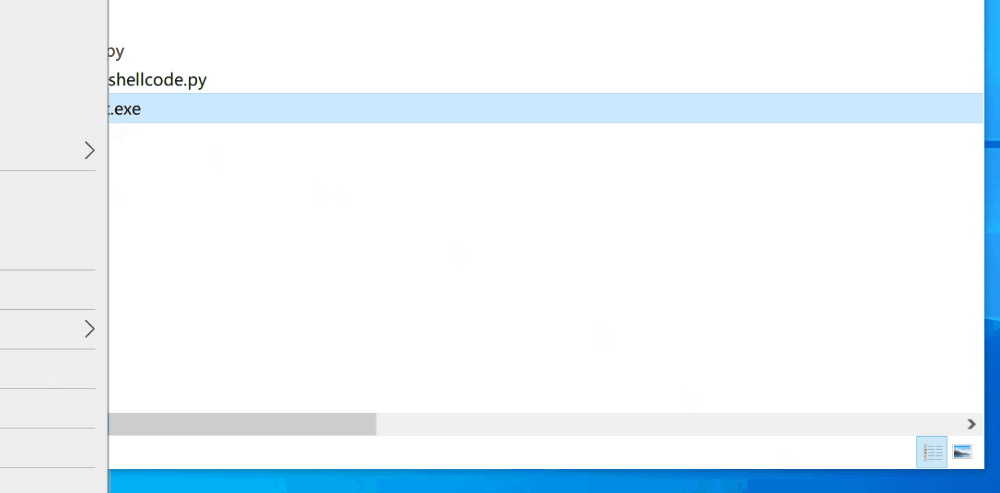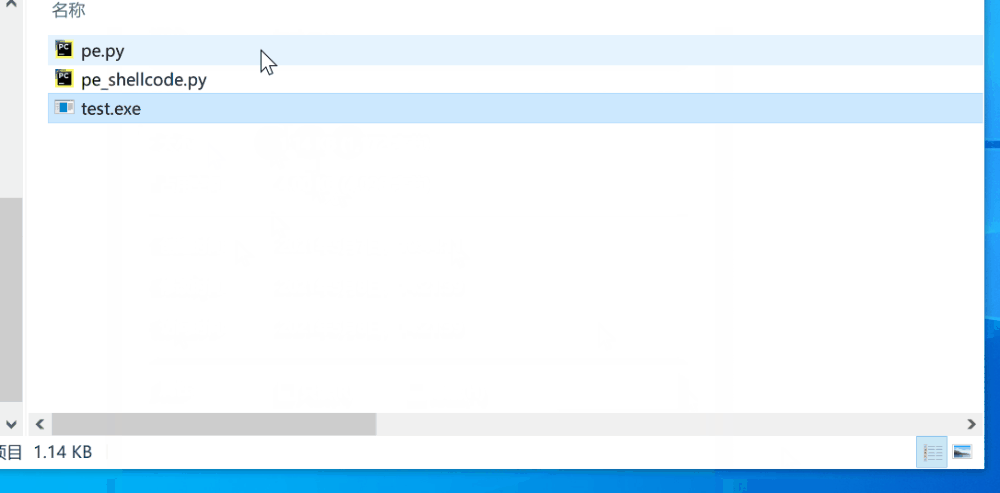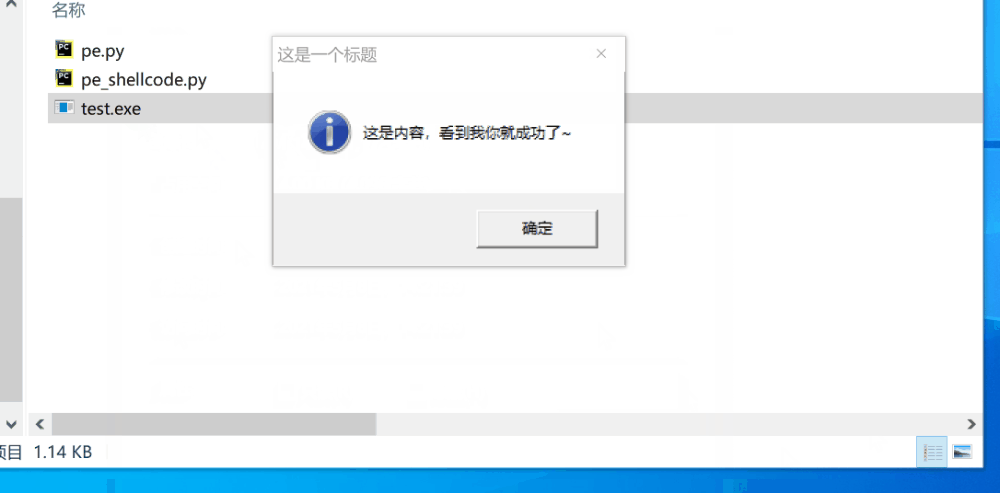
因为是根据汇编生成的机器码来的,所以需要去寻找字符串和一些dll的内存地址。我将这部分自动化了。
importer = {
"user32.dll": ["MessageBoxA"],
"kernel32.dll": ["ExitProcess"]
}
ConstString = {
"title": "这是一个标题",
"msg": "这是内容,看到我你就成功了~"
}importer代表要导入的dll和函数,ConstString 代表输入的字符串。这是text字段的代码
section_text = b""
section_text += b"\x6a\x40"
section_text += b"\x68" + replaceTable["title"] # cccccc01 后面用作替换 title
section_text += b"\x68" + replaceTable["msg"] # cccccc02 后面用作替换 msg
section_text += b"\x6a\x00"
section_text += b"\xff\x15" + replaceTable["MessageBoxA"] # cccccc03 messagebox地址
# push 40 // style
# push title
# push text
# push 0 // hwnd
# call messagebox
section_text += b"\x6a\x00"
section_text += b"\xff\x15" + replaceTable["ExitProcess"] # cccccc04 exitprocess地址
# push 0
# call exitprocess最后生成代码会自动对这些地址进行替换。
代码地址:学习pe,用python生成pe文件 (github.com)
第三部 x64 + 导入表
32位的搞定了,再看看64位的,PE结构上的差异就几个地方。主要是header头和导入表,写一个新的结构进去就行。
typedef struct _IMAGE_NT_HEADERS64 {
DWORD Signature;
IMAGE_FILE_HEADER FileHeader;
IMAGE_OPTIONAL_HEADER64 OptionalHeader;
} IMAGE_NT_HEADERS64, *PIMAGE_NT_HEADERS64;
typedef struct _IMAGE_NT_HEADERS {
DWORD Signature;
IMAGE_FILE_HEADER FileHeader;
IMAGE_OPTIONAL_HEADER32 OptionalHeader;
} IMAGE_NT_HEADERS32, *PIMAGE_NT_HEADERS32;typedef struct _IMAGE_THUNK_DATA64 {
union {
ULONGLONG ForwarderString; // PBYTE
ULONGLONG Function; // PDWORD
ULONGLONG Ordinal;
ULONGLONG AddressOfData; // PIMAGE_IMPORT_BY_NAME
} u1;
} IMAGE_THUNK_DATA64;
typedef IMAGE_THUNK_DATA64 * PIMAGE_THUNK_DATA64;
#include "poppack.h" // Back to 4 byte packing
//@[comment("MVI_tracked")]
typedef struct _IMAGE_THUNK_DATA32 {
union {
DWORD ForwarderString; // PBYTE
DWORD Function; // PDWORD
DWORD Ordinal;
DWORD AddressOfData; // PIMAGE_IMPORT_BY_NAME
} u1;
} IMAGE_THUNK_DATA32;
typedef IMAGE_THUNK_DATA32 * PIMAGE_THUNK_DATA32;然后x64 的调用约定和call的方式也不一样
x64调用约定
在32位汇编中,我们调用一个API时,采用的是stdcall,它有两个特点:一是所有参数入栈,通过椎栈传递;二是被调用的API负责栈指针(ESP)的恢复,我们在调用MessageBox后不用add esp,14h,因为MessageBox已经恢复过了。
x64 call偏移地址计算
参考
代码地址(x64) https://gist.github.com/boy-hack/dbfef2a3eff6b7b00791f6a9714b8aea
将win64改成True就会生成64位的程序了
代码完成了
- 代码完成了call偏移地址自动计算
- 自动置入字符串,自动计算字符串位置
- 代码基本上只需自定义’文本’,’导入函数’,和调用代码,其他的绝对地址转换会自动实现
End
- 因为用了一些代码自动寻找地址,一度以为可以用python写exe了(定义好导入的函数和常量,text代码段可以自定义之类的)
- 对一些PE字段的定义,区块对齐,地址的转换,程序如何调用dll有了更深的了解